
Lasso e Ridge sono due differenti metodi statistici che permettono la selezione automatica delle variabili. Tali tecniche possono essere utili nel momento in cui si vogliono vincolare i coefficienti dei predittori in modo tale che assumano valori molto prossimi a zero o addirittura pari a zero. Sono metodi spesso utilizzati quando il numero di predittori (p) è elevato, ovvero nei contesti di “Big Data”. Tali metodi sono spesso detti di metodi di shrinkage (rimpicciolimento). Vediamo ora la differenza sostanziale tra i due.
Ridge Regression
Il metodo di ridge regression è un metodo pressoché simile ai minimi quadrati lineari, i quali permettono di trovare i Beta stimati minimizzando la somma dei quadrati dei residui (RSS):
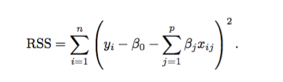
La ridge regression, al fine di stimare i Beta, parte dalla formula base dell’ RSS e vi aggiunge il termine di penalità: il λ (≥ 0) (lambda) è definito parametro di tuning, il quale moltiplicato per la sommatoria dei coefficienti Beta al quadrato (esclusa l’intercetta) definisce il termine di penalità.
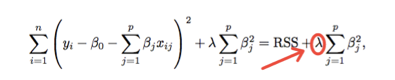
Risulta evidente che avere un λ = 0 significa non avere una penalità nel modello, ovvero produrremmo le stesse stime che con i minimi quadrati (OLS). In altro modo avere un λ → ∞ (molto grande) significa avere un effetto di penalità elevato, che porterà molti coefficienti ad essere prossimi a zero, ma non implicherà l’esclusioni degli stessi dal modello. Si può inoltre notare che aumentando il parametro di tuning (λ) si ha una minore flessibilità del modello, il quale comporterà una varianza minore, ma un bias maggiore. Una scelta ottimale di λ permette di trovare il giusto compromesso tra bias e varianza. Se il numero di predittori è elevato ma minore della numerosità (p < n) l’utilizzo degli OLS potrebbe riscontrare alcune difficolta in seguito all’elevata variabilità. Se il numero di predittori è superiore alla numerosità (p > n) gli OLS non possono essere usati. In entrambi i casi, il metodo ridge può fare il suo lavoro. Il metodo di ridge regression non permette mai l’esclusione dei Beta stimati simili a 0 dal modello. Tale mancanza, dal punto di vista della precisione della stima può non essere un problema. Un problema connesso a tale limite è sul lato dell’interpretabilità dei coefficienti, dato l’elevato numero di predittori.
Lasso
Il metodo lasso (least absolute shrinkage and selection operator) va a colmare lo svantaggio della ridge regression. Permette ai coefficienti dei beta stimati di essere esclusi dal modello quando sono pari a zero. Si può notare che la formula della ridge regression è molto simile a quella del lasso, l'unica differenza consiste nella struttura della penalità, in quanto bisogna calcolare la sommatoria del valore assoluto dei Beta.
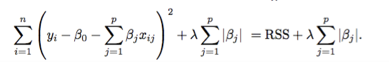
Come nella ridge regression il metodo lasso costringe i coefficienti stimati verso lo zero ma, la il valore assoluto presente, costringe alcuni di essi ad essere esattamente pari a zero. Questa situazione si può verificare in presenza di un parametro di tuning (λ) elevato. In questo caso posso fare una selezione delle variabili ed escluderle dal modello. Come nel caso analogo, quando il valore di lambda è prossimo a zero (λ = 0) significa che non si ha una penalità nel modello, ovvero le stime prodotte sono le stesse ottenute dai minimi quadrati. Differentemente se il valore di lambda assume numero elevati (λ -> ∞) il modello fornito è un modello nullo. Si parla di modello nullo in quanto tutti i coefficienti sono pari a zero l’unico valore differente è quello dell’intercetta che è stata esclusa a priori da tale metodo. In entrambi i modelli, per determinare il valore del parametro di tuning (λ), un buon metodo sarebbe quello di usare la validazione incrociata (cross validation).
I due modelli a confronto
Da un punto di vista matematico i due metodi possono considerarsi diversi perché posti sotto vincoli leggermente differenti. Nel primo caso abbiamo il vincolo relativo al modello lasso mentre nel secondo caso abbiamo il vincolo relativo al modello ridge regression.

Per confrontarli si può usare l’R2 calcolato sul dataset di training. In generale ci si può aspettare che la ridge regression svolga un lavoro migliore quando il numero dei predittori è elevato, e al tempo stesso che il lasso svolga un lavoro migliore quando il numero dei predittori è piccolo.
Per concludere: qual è il modello migliore? A mio modesto parere, non vi è un metodo che domina sull’altro, dobbiamo sempre trovare il giusto compromesso tra bias-varianza, come in quasi tutti i problemi di modulazione statistica.
Nel prossimo articolo vedremo insieme come utilizzare i due metodi da un punto di vista pratico, ovvero attraverso l’uso del software R.
Continuate a seguirmi!