

Negli ultimi tempi mi sono trovato a dover intervistare diverse persone per una posizione aperta in Sysdig.
Il mio compito era quello di effettuare un colloquio tecnico sulla parte frontend del mitico alerting team di cui ora faccio parte - mitico grazie ai miei straordinari colleghi 🥰 - in modo da dare un parere riguardo il candidato.
Il nostro obbiettivo era quello di trovare un senior software engineer che potesse integrarsi all'interno della squadra abbastanza velocemente.
Preparare un colloquio di lavoro è difficile quando si è nei panni del candidato: si deve ripassare la propria materia, non si conosce l'interlocutore e solitamente vi è un po' di agitazione ed emozione, specie se il posto di lavoro è ambito.
Ma nemmeno agire nei panni di colui che intervista è semplice: decidere quali domande porre non è affatto banale, tenendo in considerazione vari fattori come lo stato d'animo di chi si ha di fronte, considerando poi che ognuno di noi possiede la propia soglia di emotività.
Per come sono strutturati i colloqui classici, dove si pongono delle domande o si richiede lo svolgimento di alcuni esercizi, purtroppo l'attitudine a questo tipo di situazione porta coloro che riescono a reggere maggiormente lo stress ad essere più avvantaggiati rispetto ad altri, ed è un fattore importante da non mettere mai in secondo piano in quanto potrebbe influenzare, anche di molto, l'esito del colloquio. La risposta di un candidato apparentemente in difficoltà potrebbe essere totalmente diversa se posta in una situazione "normale".
Con questo concetto scolpito in mente, ho necessariamente dovuto preparare delle domande e degli esercizi che proporrò di seguito (alla fine abbiamo trovato il candidato giusto per cui questo post mi è utile per obbligare me stesso a cambiare domande la prossima volta 😅).
Cosa domandare per testare la seniority di un ingegnere che lavorerà per di più con il linguaggio TypeScript? Ho provato a chiedermi quali siano i concetti assolutamente indispensabili senza i quali, a mio modestissimo parere, una persona debba o non debba essere assunta per le mansioni che andrà a ricoprire nel nostro team.
La scaletta che ho preparato inizia con delle parti più soft per poi crescere di difficoltà.
Interfacce VS Tipi
Una delle principali migliorìe apportate da TypeScript è il supporto ai tipi ed il suo type checking (che sia tutto fuorché perfetto concordo, ma vuoi mettere in confronto al semplice JavaScript?) meglio quindi affrontare subito la questione: che differenza c'è tra le interfacce ed i tipi?
Doverosa premessa: TypeScript ci fornisce alcuni tipi di base pronti ad essere utilizzati, sono i classici string, boolean o number (ecco lista completa) ma oltre costoro, il linguaggio permette di definire dei tipi avanzati chiamati type aliases.
Per fare ciò si utilizza la parola chiave type in questo modo:
type Coordinata = {
x: number;
y: number;
};Ma siamo sicuri di sapere realmente cosa significhi quanto scritto?
Con questa dichiarazione stiamo creando un nuovo nome per un tipo, non stiamo definendo realmente un nuovo tipo.
Questo è un punto abbastanza importante perché spesso si tende a confondere le due cose pensando erroneamente di creare un nuovo tipo, quando invece - ripeto - si sta creando un nuovo nome (alias) per un tipo. Dunque, quando si parla della differenze tra tipo e interfaccia si da per scontato che in realtà si tratti della differenza tra alias di tipo e interfaccia.
Si potrebbe argomentare per diversi minuti al riguardo, proviamo quindi ad elencare le principali differenze.
Unione tra dichiarazioni diverse
Se utilizziamo due o più interfacce aventi lo stesso nome, il compilatore si occuperà di farne il merge per ottenere un'unica interfaccia comprendente al suo interno tutti i campi delle varie dichiarazioni.
Per esempio:
interface Libro {
autore: string;
}
interface Libro {
titolo: string;
}
// l'oggetto 'libro' è strutturato come il merge
// delle due interfacce aventi lo stesso nome
const libro: Libro = {
autore: "Pippo",
titolo: "Pluto",
};La medesima dichiarazione è impossibile utilizzando i tipi per cui se provassimo, otterremmo un errore.
La documentazione riguardo il declaration merging è molto ben fatta, se siete curiosi e volete approfondire vi invito a darle un'occhiata.
Extends
Le interfacce possono estendersi a vicenda, questo consente di copiare i campi di un'interfaccia in un'altra, con la possibilità di sovrascriverne alcuni e aggiungerne di nuovi. È uno strumento che offre flessibilità nel modo di organizzare le interfacce per essere riutilizzate. Chi proviene dalla programmazione ad oggetti avrà probabilmente presente il concetto di ereditarietà, che è alla base di questo meccanismo.
interface Figura {
colore: string;
}
interface Poligono extends Figura {
numeroLati: number;
}
// l'oggetto poligono contiene sia le caratteristiche
// di Figura che quelle proprie del Poligono
const poligono: Poligono = {
colore: 'blu',
numeroLati: 3,
};Si può anche estendere più di un'interfaccia per volta:
interface Figura {
colore: string;
}
interface TrattoPenna {
spessorePenna: number;
}
interface Poligono extends Figura, TrattoPenna {
numeroLati: number;
}
const poligono: Poligono = {
colore: 'blu',
numeroLati: 3,
spessorePenna: 1,
};I type aliases non prevedono la possibilità di estendersi tra loro, anche se vi è qualcosa di analogo che vedremo in seguito, però dalla versione 2.2 un'interfaccia può estendere un tipo, che è molto utile:
type Impiegato = {
cognome: string;
nome: string;
}
interface Manager extends Impiegato {
targaAuto: string;
}Da sottolineare che non è possibile utilizzare questa sintassi nel verso contrario: un tipo non può estendere un'interfaccia.
Inoltre, un'interfaccia può estendere solo un tipo con un insieme di proprietà note, poiché il compilatore deve verificare che i tipi delle proprietà dichiarate nell'interfaccia sono compatibili con i tipi delle proprietà corrispondenti nel tipo di base (se presenti).
Nel seguente esempio l'interfaccia estende correttamente il type alias perché quest'ultimo contiene un insieme di proprietà note ed il compilatore può verificare che l'attributo descrizione, seppur usato in entrambi, è compatibile in quanto trattasi dello stesso tipo:
type Prodotto = {
id: number,
descrizione: string
};
interface Libro extends Prodotto {
descrizione: string,
titolo: string,
}Un esempio in cui invece un'interfaccia non può estendere un type alias è quando quest'ultimo non presenta una lista di membri noti:
type Prodotto<T> = {
[P in keyof T]: number
}
interface Libro extends Prodotto<number> {
id: number,
titolo: string,
}con relativo messaggio:
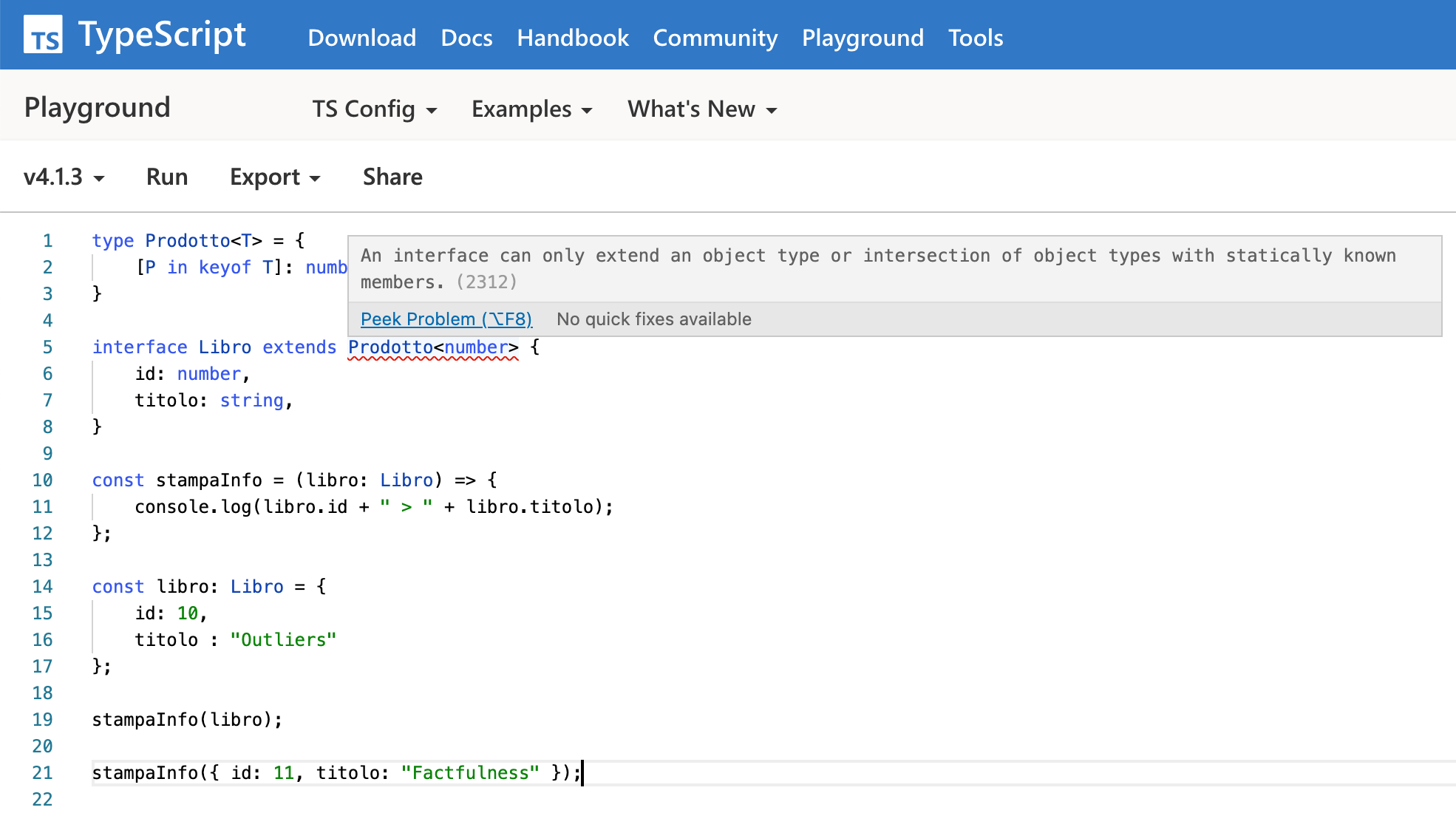
Implements
Le interfacce in TypeScript possono anche essere implementate con una classe, proprio come avviene in Java o C#.
La classe che implementa l'interfaccia deve essere strettamente conforme alla struttura di quest'ultima:
// 'IImpiegato' non è un errore,
// la prima 'I' sta per Interfaccia
interface IImpiegato {
matricola: number;
nome: string;
getStipendio: (matricola: number) => number;
}
class Impiegato implements IImpiegato {
matricola: number;
nome: string;
constructor(matricola: number, nome: string) {
this.matricola = matricola;
this.nome = nome;
}
getStipendio(matricola:number): number {
return 40000;
}
}
const imp = new Impiegato(1, 'Marco');
// stampa 'Marco - 40000'
console.log(`${imp.nome} - ${imp.getStipendio(1)}`
Ovviamente, la classe può contenere proprietà o metodi extra, ma deve definire almeno tutti i membri specificati nell'interfaccia.
Questo è il modo concreto con cui TypeScript ci permette di usare il polimorfismo, infatti una classe può implementare più interfacce per volta:
interface Autore {
nome: string,
}
interface Libro {
titolo: string,
}
class Prodotto implements Autore, Libro {
nome: string;
titolo: string;
constructor(nome: string, titolo: string) {
this.nome = nome;
this.titolo = titolo;
}
}
const prod = new Prodotto('Malcolm Gladwell', 'Outliers');
// stampa 'Malcolm Gladwell - Outliers'
console.log(`${prod.nome} - ${prod.titolo}`)Unione
Può capitare che il tipo di una proprietà, di una costante o di una variabile non sia sempre definito a priori ma possa assumere diverse tipologie di valori.
Il tipo unione - Union Type - permette di descrive questa situazione: un valore che può essere di vario tipo. Per specificare la lista dei tipi che può assumere il valore, usiamo la barra verticale | tra un tipo e l'altro.
type Tipo = number | string | boolean;
const a: Tipo = 10; // ok
const b: Tipo = 'ciao'; // ok
const c: Tipo = true; // ok
// errore: 'd' è un array di numeri
// ma Array<number> non rientra
// nell'elenco dei possibili tipi
const d: Tipo = [10];Forse il prossimo esempio può aiutare la comprensione:
type Uomo = {
nome: string
};
type Donna = {
nome: string
};
// tipo Persona che può essere di tipo Uomo o Donna
type Persona = Uomo | Donna;
const persona: Persona = {
nome: 'Andrea',
};
console.log(persona.nome) // stampa 'Andrea'Una cosa carina è la possibilità di creare un nuovo tipo unione combinando due interfacce (ma non possiamo creare un'interfaccia che combini due tipi):
interface Uomo {
nome: string
}
interface Donna {
nome: string
}
type Persona = Uomo | Donna;
const persona: Persona = {
nome: 'Giulia',
};
console.log(persona.nome) // stampa 'Giulia'Intersezione
Il tipo intersezione - Intersection Type - ci consente di combinare più tipi fra loro ed ottenerne uno solo con tutte le proprietà al suo interno.
Per creare un'intersezione, dobbiamo usare &:
type Nome = {
nome: string
};
type Eta = {
eta: number
};
type Persona = Nome & Eta;
const persona: Persona = {
nome: 'Andrea',
eta: 33
};
// stampa 'Andrea - 33'
console.log(`${persona.nome} - ${persona.eta}`)Simile a quanto già visto per le unioni, possiamo creare un nuovo tipo intersezione combinando due interfacce (ma, al solito, non viceversa):
interface Nome {
nome: string
};
interface Eta {
eta: number
}
type Persona = Nome & Eta;
const persona: Persona = {
nome: 'Flavio',
eta: 18
};
// stampa 'Flavio - 18'
console.log(`${persona.nome} - ${persona.eta}`)Tuple
Una menzione speciale la meritano le tuple, una struttura dati importante.
Il tipo tupla consente di esprimere array con particolari caratteristiche: un numero fisso di elementi ed il tipo degli elementi che lo compongono noto a priori, perdipiù essi possono anche essere eterogenei.
Ad esempio, potremmo voler definire un tipo per rappresentare le coppie chiave-valore come una tupla stringa-numero:
type ImpiegatoMatricola = [string, number];
const impiegato1: ImpiegatoMatricola = ['Massimo', 1000001]; // ok
const impiegato2: ImpiegatoMatricola = [1000002, 'Marco']; // errorePossiamo dichiarare tuple solo utilizzando i tipi, se usiamo un'interfaccia, le tuple possono essere usate al suo interno:
interface ImpiegatoMatricola {
valore: [string, number],
}
// ok
const impiegato1: ImpiegatoMatricola = {
valore: ['Massimo', 1000001]
};
// errore
const impiegato2: ImpiegatoMatricola = {
valore: [1000002, 'Marco']
};Quindi, cosa utilizzare?
Nessuno è meglio dell'altro, peraltro possono anche essere usati in combinazione quindi l'impiego di uno non esclude l'altro.
Questi sono alcuni degli strumenti messi a disposizione dal linguaggio, è responsabilità dell'utilizzatore scegliere cosa sia più adatto rispetto al problema che deve risolvere, ai fini di un colloquio a mio avviso l'importante è dimostrare di avere chiara la differenza tra questi due mezzi.
Il concetto di Duck Typing

Un'altra domanda per capire quanto una persona abbia familiarità con TypeScript riguarda la sua politica di controllo dei tipi.
Il modo di fare inferenze su di essi, detto duck typing, si riferisce a uno stile di tipizzazione dinamica dove la semantica di un oggetto è determinata dall'insieme corrente dei suoi metodi e delle sue proprietà anziché dal fatto di estendere una particolare classe o implementare una specifica interfaccia, da qui la famosa frase che sintetizza tale pensiero:
Se cammina come un'anatra e starnazza come un'anatra, deve essere un'anatra...
Nel duck typing si è interessati solo alle caratteristiche di un oggetto invece che al suo tipo. Teoricamente il vantaggio è quello di non aver bisogno di confrontare il tipo degli argomenti nei metodi e nei corpi delle funzioni. Alcuni sostengono che aggiungere questo controllo prima del run-time, assegnando esplicitamente i tipi in quei punti del codice, limiti i benefici e la flessibilità del duck typing perché in tal modo si vincolerebbe il dinamismo del linguaggio. Nel contesto dell'utilizzo di TypeScript, io non sono d'accordo con questa linea di pensiero, proprio perché se abbiamo deciso di utilizzare quest'ultimo anziché semplice JavaScript, è perché vogliamo un type checking più rigoroso a compile time che JS non fornisce.
Facciamo un esempio concreto: definiamo tre interfacce rappresentanti tre animali diversi, una funzione che, passato uno solo di essi, emetta il suo verso e tre oggetti per verificare il comportamento:
// 3 interfacce di 3 animali diversi
interface Cane {
verso: () => string;
}
interface Leone {
verso: () => string;
}
interface Capra {
verso: () => string;
nuota: () => string;
}
// passato un Cane, emette il suo verso
const faiVerso = (cane: Cane) => {
console.log(cane.verso());
}
// 3 oggetti di animale diverso
const cane: Cane = {
verso: () => 'Bau!',
};
const leone: Leone = {
verso: () => 'Roarrr!',
};
const capra: Capra = {
verso: () => 'Beeeee!',
nuota: () => 'Mi spiace, non so nuotare',
};
// (1) stampa 'Bau!'
faiVerso(cane);
// (2) stampa 'Roarrr!'
faiVerso(leone);
// (3) creazione oggetto inline
// stampa 'Miao!'
faiVerso({
verso: () => 'Miao!'
});
// (4) stampa 'Beeeee!'
faiVerso(capra)Sebbene Cane e Leone siano due interfacce diverse, esse hanno la stessa struttura pertanto il compilatore le considera la stessa cosa (ecco l'essenza del concetto di duck typing) per cui, anche se la funzione faiVerso richiede un oggetto di tipo Cane, pur passando un oggetto Leone non avremo nessun problema, come mostrato nelle chiamate (1) e (2) del codice.
In (3) viene illustrato come persino un oggetto creato inline vada bene, dato che quest'ultimo implicitamente implementa l'interfaccia Cane.
Per quanto riguarda l'ultima chiamata di faiVerso, punto (4), nonostante il tipo Capra abbia una struttura diversa, essa contiene la funzione verso() dunque anche quest'ultima linea di codice non desta problemi.
Diversa sarebbe stata la situazione se la fuzione faiVerso avesse richiesto in input un oggetto di tipo Capra:
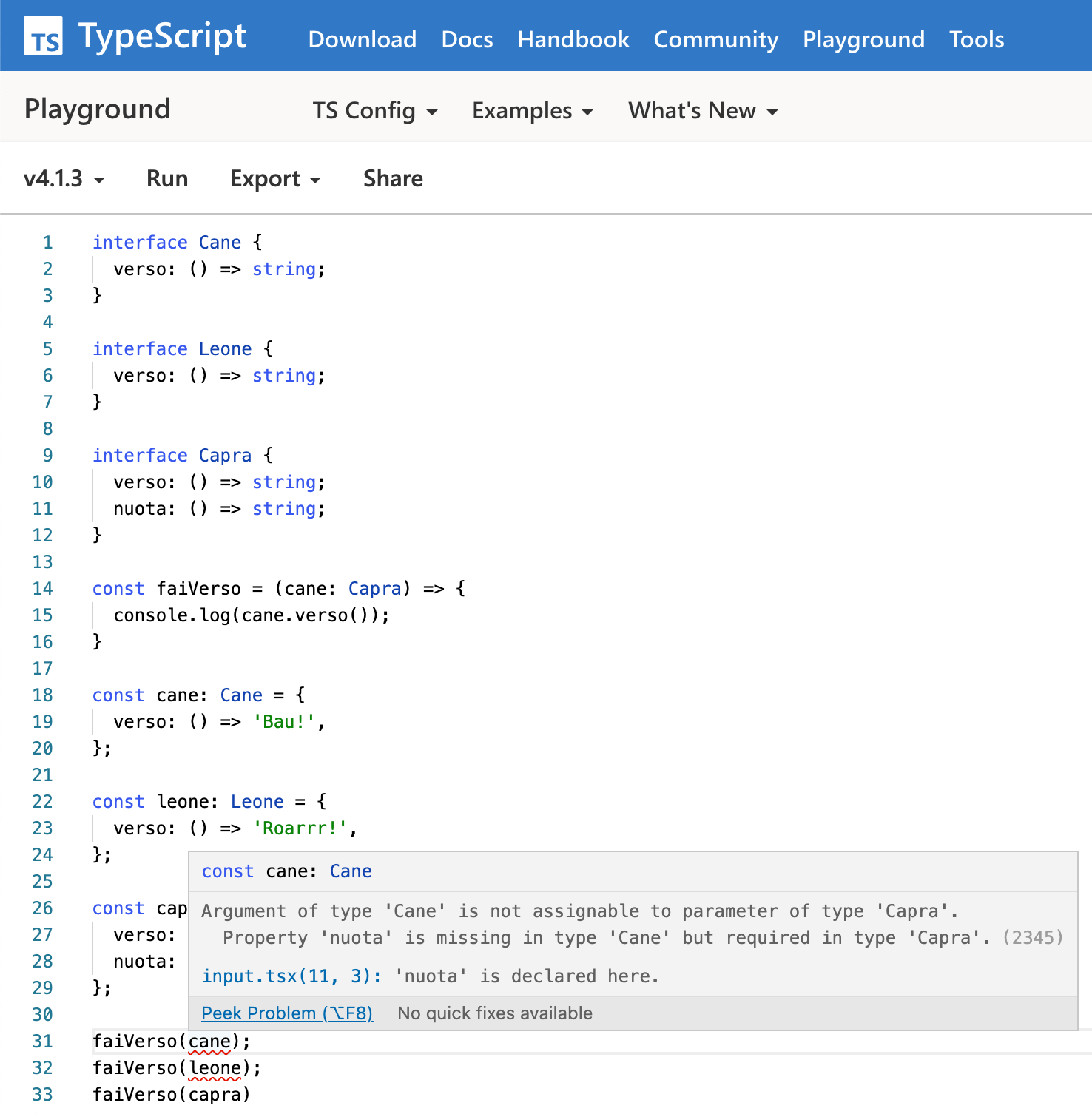
Il motivo dell'errore è che l'interfaccia Cane (ma ugualmente accade per Leone) non ha al suo interno la funzione nuota(), specificata invece da Capra, il tipo dell'oggetto che si aspetta come parametro la funzione faiVerso.
Closure
Un concetto importantissimo quando si lavora con TypeScript o JavaScript è quello della closure.
Una closure è la possibilità, per una funzione, di referenziare il suo stato circostante, per esempio per accedere alle variabili definite all'esterno della stessa. In altre parole, con le closure si ha accesso all'ambito esterno di una funzione e vengono create nel momento in cui viene creata la funzione.
function creaFunzione() {
// costante locale di "creaFunzione"
const nome = 'Andrea';
// definizione funzione interna, una closure
function stampaNome() {
// accede alla costante "nome"
// definita nella funzione padre
console.log(nome);
}
// ritorna la funzione
return stampaNome;
}
const stampa = creaFunzione();
// esegue la funzione "stampaNome"
// e stampa "Andrea"
stampa();Possiamo notare come la funzione interna stampaNome viene restituita dalla funzione esterna creaFunzione senza essere eseguita.
In alcuni linguaggi di programmazione, le variabili locali all'interno di una funzione esistono solo per tutta la durata dell'esecuzione della funzione stessa, dunque una volta che creaFunzione termina, ci si potrebbe aspettare che nome non sia più accessibile.
Anche se a prima vista potrebbe sembrare poco intuitivo, in JavaScript non è così: grazie alla closure, quando viene eseguita la funzione stampa, viene chiamata la funzione stampaNome che può accedere all'ambiente esterno rispetto a dove è stata definita e leggere nome senza problemi dato che le funzioni annidate hanno accesso alle variabili dichiarate al loro esterno.
Una spiegazione un po' più tecnica
Più precisamente, una closure è la combinazione di una funzione e dell'ambiente all'interno del quale quella funzione viene dichiarata. Questo ambiente è costituito da tutte le variabili locali presenti in quell'ambito al momento della sua creazione. In questo caso, stampa è un riferimento all'istanza della funzione stampaNome che viene creato quando viene eseguita creaFunzione. L'istanza di stampaNome mantiene un riferimento al suo ambito, chiamato in gergo tecnico lexical environment, all'interno del quale troviamo la costante nome. Per questo motivo, quando viene eseguita stampa, nome rimane accessibile e il suo valore viene correttamente passato al console.log di stampaNome.
Esercizio
Come potete ben capire da questa spiegazione, degli esempi concreti sono più congeniali durante una interview per cui invece di chiedere esplicitamente cosa sia, la mia idea è stata quella di dare un esercizietto in cui, per risolverlo, è necessario utilizzare tale principio.
Ho ascoltato un consiglio da un collega particolarmente brillante il quale mi ha suggerito di provare a chiedere l'implementazione della funzione expect di Jest, che noi utilizziamo con React Testing Library per testare i nostri componenti sviluppati in React.
L'idea mi è piaciuta parecchio ed ho cercato di creare un esercizio non troppo difficile: abbiamo due funzioni, una che somma due numeri mentre l'altra li sottrae.
const sum = (a: number, b: number) => a + b;
const subtract = (a: number, b: number) => a - b;Vogliamo testare queste due funzioni in modo da esser sicuri che facciano il loro lavoro senza bug, per cui vorremmo scrivere dei test di questo tipo:
const testSum = () => {
const result = sum(3, 7);
const expected = 10;
expect(result).toBe(expected);
};
const testSubtract = () => {
const result = subtract(7, 3);
const expected = 4;
expect(result).toBe(expected)
};
testSum();
testSubtract();Come implementereste la funzione expect?
Vorremmo che essa lanci un errore quando il risultato result è diverso da quello atteso in expected, e che invece non faccia nulla quando il tutto è corretto.
Se volete cimentarvi a trovare una vostra implementazione, non andate avanti a leggere.
Lo reputo un esercizio molto carino per cui fare un tentativo ne vale la pena! 😊

Utilizzando il concetto di closure visto in questo paragrafo, possiamo scrivere l'implementazione in questo modo:
function expect(actual) {
return {
toBe: (expected) => {
if (actual !== expected) {
throw new Error(`${actual} is not equal to ${expected}`)
}
},
}
}Le funzione expect, che prende come parametro un valore, può ritornare un oggetto con al suo interno la definizione di un'altra funzione, chiamata toBe, che prende a sua volta come parametro un altro valore.
A questo punto abbiamo imparato che toBe è solamente la definizione della funzione ed essa viene eseguita quando richiamata all'interno di testSum() o testSubtract() nel nostro caso.
Come possiamo notare, all'interno di toBe avviene il confronto tra i due parametri actual ed expected e, nel caso siano diversi, viene lanciato un errore. Il parametro expect è quindi parte dell'ambito esterno di toBe per cui è disponibile quando essa viene chiamata, proprio perché rappresenta una closure.
Un vantaggio di questa implementazione è che l'oggetto ritornato da expect può essere facilmente esteso andando ad aggiungere eventuali altre funzioni di controllo.
Immutabilità, programmazione funzionale e dichiarativa
Ho pensato che un'altra parte dell'interview utile a capire il livello d'esperienza del candidato, potesse essere dedicata alla risoluzione di alcuni esercizi apparentemente facili per controllare come vengono affrontati. Da un senior mi aspetto soluzioni che tengano conto dell'immutability, con uno stile di programmazione il più possibile dichiarativo.
Non a caso ho messo questi concetti nello stesso paragrafo, sebbene diversi, essi sono legati tra loro nel contesto in cui ci troviamo, vediamo come.
La programmazione funzionale è un paradigma in cui i programmi vengono costruiti utilizzando e componendo funzioni.
Nella programmazione funzionale orientata agli oggetti, se un oggetto non può essere modificato dopo la sua creazione, esso si dice immutabile.
Si dice funzionale per riprendere il significato matematico della parola funzione: una trasformazione, o mappa, che preso un argomento di un certo valore all'interno di un dominio, ne produce uno in uscita verso un altro dominio, chiamato codominio. Le funzioni matematiche non specificano come questa mappatura debba avvenire, si limitano a rappresentarla.
Le funzioni dei linguaggi procedurali o imperativi sono invece delle procedure piuttosto che delle funzioni, poiché contengono e svolgono delle mere direttive di calcolo. Di contro, la funzione matematica non esegue calcoli ma si limita a mappare valori.
La programmazione dichiarativa è uno stile di programmazione non imperativo in cui i programmi descrivono i risultati desiderati senza elencare esplicitamente i comandi o i passaggi che devono essere eseguiti.
Si dice dichiarativa perché le funzioni esprimono la logica di calcolo piuttosto che contenere una sequenza di istruzioni imperative che aggiornano lo stato di esecuzione del programma.
I linguaggi di programmazione funzionali sono solitamente caratterizzati da uno stile di programmazione dichiarativo, per approfondire l'argomento mi sento di consigliare questo bell'articolo.
Come consegenza della programmazione funzionale, ad ogni insieme unico di configurazione di input, deve corrispondere sempre e solo un unico risultato di output (che è poi la definizione di funzione matematica univoca).
Ed ecco dove entra in gioco l'immutabilità: questo principio è molto più facile da rispettare se non vi sono mutazioni di stato nel programma!
Uno dei punti forti dell'immutabilità riguarda le performance in termini di tempo.
Assumiamo di avere un oggetto, se cambiamo una proprietà al suo interno avremo bisogno di molto tempo affinché JavaScript (o TypeScript, che ricordiamo esserne un soprainsieme) riconoscano la novità: si dovrebbero confrontare tutti i valori delle proprietà all'interno dell'oggetto prima della modifica, una ad una, con quelli nuovi, per capire quante e quali siano cambiate.
Con l'immutabilità il confronto è molto più economico: per capire se un oggetto è cambiato o meno, basterà controllare solo il suo riferimento. Poiché ogni qual volta che una o più proprietà al suo interno cambiano, un nuovo oggetto, che prenderà il posto di quello precedente, verrà creato, esso avrà un indirizzo di memoria diverso, pertanto il confronto risulterà velocissimo (basterà confrontare l'indirizzo di due oggetti e constatare che siano uguali o diversi).
Librerie come React si basano sul concetto di immutabilità per le loro performance, ecco perché diamo tanta enfasi a concetti come questi, saperli padroneggiare è fondamentale per progettare e sviluppare applicazioni web ad elevate prestazioni.
Tornando a JavaScript, il nostro caro linguaggio non è così pratico quando ci si deve confrontare con l'immutabilità: internamente, tutti i tipi di dati primitivi (stringa, numeri, booleani ecc...) sono immutabili, il che significa che non è possibile modificare il loro valore una volta assegnato ad una variabile. Si può solamente assegnare un nuovo valore ad una variabile precedentemente inizializzata ed il vecchio valore verrà smaltito dal garbage collector quando sarà il momento.
Con gli oggetti il funzionamento è diverso: si può sovrascrivere il valore di una proprietà, aggiungere o rimuovere dei campi ogni volta che lo si desidera:
const obj = { a: 1 }; // definizione di un oggetto
obj.b = 2; // aggiunge una nuova proprietà b
obj.c = 'hello'; // aggiunge una nuova proprietà c
obj.b = 3; // aggiorna la proprietà b
delete obj.b; // elimina la proprietò bGli oggetti sono mutabili e vengono passati per riferimento. Quando si assegna un oggetto ad una variabile, il valore dell'oggetto non viene copiato: JavaScript assegna alla variabile solo il riferimento a quell'oggetto. Lo stesso principio si verifica quando si passa un oggetto come argomento aD una funzione o si restituisce un oggetto da una funzione.
A complicare un altro po' le cose ci si mette il linguaggio stesso: JavaScript offre nativamente dei metodi che cambiano la struttura dati su cui sono chiamati.
Prendiamo la funzione push che aggiunge un elemento ad un array:``
const nomi = ['andrea', 'giulia', 'serena'];
nomi.push('michele');
// stamperà ['andrea', 'giulia', 'serena', 'michele']
console.log(nomi); Come possiamo notare dall'esempio, dopo l'aggiunta del nuovo elemento, se stampiamo il contenuto dell'array di nomi originario, esso conterrà anche quest'ultimo poiché il metodo push modifica la struttura dati originale. Questo è un esempio di quello che non vogliamo ottenere.
Dunque come facciamo a conservare l'immutabilità?
Vi sono diversi modi per farlo: utilizzare librerie esterne, "congelare" un oggetto dandolo in pasto ad Object.freeze() che lo renderà non modificabile, oppure agire direttamente sulla nostra tecnica di programmazione. Quest'ultimo è il mio preferito perché si tratta il problema in modo esplicito e mette in evidenza le scelte effettuate durante la stesura del codice.
Vediamo dunque come potrebbero essere risolti i seguenti esercizi in modo che rispettino le premesse fatte in questo paragrafo; il fine è appurare che chi li svolga sia consapevole di tutto questo scenario e ne tenga conto nel fornire la soluzone.
interface Oggetto {
id: number;
nome: string;
inMagazzino: boolean;
}
// creo 99 oggetti, alcuni in magazzino ed altri no
const oggetti: Oggetto[] = Array.from({ length: 99 },
(_, index) => ({
id: index + 1,
nome: `oggetto-${index + 1}`,
inMagazzino: index % 2 === 0,
})
);
// 1. inserire in questa costante tutti gli oggetti in magazzino
const oggettiInMagazzino = null;
// 2. creare una mappa di coppie chiave-valore la cui chiave
// sia l'id dell'oggetto ed il valore l'informazione
// riguardante la sua presenza in magazzino o meno
const mappaOggetti = null;
// 3. gli oggetti con id compresi tra 20 e 40 (estremi inclusi)
// necessitano di un formato differente nel campo nome, invece
// di avere 'oggetto-25' ora dovranno avere
// 'oggetto-25-in-sconto'; agire di conseguenza.Di seguito fornirò una mia interpretazione di questi esercizi: come sempre accade in queste occasioni, non vi è un'unica soluzione ma ognuno è libero di risolverli come meglio crede. Ė probabile che vi siano soluzioni migliori, spiegherò comunque le scelte implementative di seguito. La cosa veramente importante è che prima di proseguire facciate un tentativo autonomo per poi confrontare, e magari perché no, discutere assieme, le differenze tra quanto fatto da me e la vostra risoluzione.
interface Oggetto {
id: number;
nome: string;
inMagazzino: boolean;
}
// creo 99 oggetti, alcuni in magazzino ed altri no
const oggetti: Oggetto[] = Array.from({ length: 99 },
(_, index) => ({
id: index + 1,
nome: `oggetto-${index + 1}`,
inMagazzino: index % 2 === 0,
})
);
// 1. inserire in questa costante tutti gli oggetti in magazzino
const oggettiInMagazzino = oggetti.filter(
(oggetto: Oggetto) => oggetto.inMagazzino
);
// 2. creare una mappa di coppie chiave-valore la cui chiave
// sia l'id dell'oggetto ed il valore l'informazione
// riguardante la sua presenza in magazzino o meno
interface MappaOggetti {
[key: number]: boolean
}
const mappaOggetti = oggetti.reduce(
(mappa: MappaOggetti, oggetto: Oggetto) => {
const { id, inMagazzino } = oggetto;
mappa[id] = inMagazzino;
return mappa;
}, {}
);
// 3. gli oggetti con id compresi tra 20 e 40 (estremi inclusi)
// necessitano di un formato differente nel campo nome, invece
// di avere 'oggetto-25' ora dovranno avere
// 'oggetto-25-in-sconto'; agire di conseguenza.
const oggettiAggiornati = oggetti.map(
(oggetto: Oggetto) => {
const { id } = oggetto;
if (id < 20 || id > 40) return oggetto;
return {
...oggetto,
nome: `oggetto-${id}-in-sconto`,
};
}
);Per il primo esercizio ho usato la funzione filter perché non modifica l'array di oggetti originario ma ne crea una copia, includendo al suo interno solamente gli elementi che passano il controllo implementato nella funzione passata come parametro (nel nostro caso specifico tutti quelli la cui proprietà inMagazzino è uguale a truthy). Se stampassimo oggetti vedremmo che al suo interno sono contenuti esattamente gli stessi elementi che avevamo prima della creazione di oggettiInMagazzino. Inoltre, leggendo la linea che risolve l'esercizio, si può intuire cosa faccia dalla sola lettura: possiamo ritenerci abbastanza soddisfatti in quanto stiamo rispettando i princìpi illustrati in questo paragrafo: il codice non muta le strutture dati che manipola, è sufficientemente funzionale e dichiarativo.
Nell'esercizio successivo ho invece creato un'interfaccia che esplicita il tipo della mappa rispecchiando quanto chiesto dalla consegna, dopodiché ho usato reduce: a dire il vero non è una funzione dichiarativa ed è spesso difficile da seguire se al suo interno vi sono molte istruzioni complesse. Questo metodo esegue la funzione passata come parametro su ciascun elemento dell'array originario. La cosa carina è che nella callback, come primo parametro - nel nostro caso trattasi di mappa - viene reso disponibile il valore restituito dal calcolo delle iterazioni precedenti. Il risultato finale sarà un valore singolo proveniente dall'applicazione della funzione su tutti gli elementi dell'array. Potete capire che, se usato con parsimonia, questo metodo può tornare molto utile. In questo caso non facciamo altro che aggiungere elementi alla mappa man mano che scorriamo l'array di oggetti, pertanto mi è parso di farne un uso legittimo.
Per finire ci è richiesto di cambiare il nome di alcuni oggetti. Riconosco che la richiesta è un po' vaga e non specifica come comportarsi: tutto questo è appositamente escogitato per vedere se tale situazione crea della curiosità o dei dubbi al candidato, portandolo a porre delle domande al suo interlocutore.
Proseguendo alla stregua della strategia intrapresa fino ad ora, questa volta ho utilizzato map: anche lei non modifica il contenuto dell'array originario, bensì ne crea una copia popolandolo con i risultati della funzione passata come parametro chiamata su ogni elemento dell'array originario. Al suo interno utilizziamo lo spread operator nei casi in cui è richiesto cambiare formato al nome dell'elemento. Questo ci semplifica il lavoro perché ci permette di copiare tutte le proprietà dell'oggetto sovrascrivendo solo nome nel nuovo formato.
Come premesso, vi sono altri infiniti modi di risolvere esercizi del genere. L'importante per me è constatare che chi si trova alle prese con queste sfide, riconosca i concetti illustrati in questo paragrafo e risolva gli esercizi tenendone conto.
Conclusioni
In questo articolo non abbiamo visto tutto l'arsenale di possibili domande, un po' perché mi sono fatto prendere la mano durante la stesura e forse è già troppo lungo così, con il rischio di annoiare chi legge; un po' perché nel caso qualcun altro debba fare l'interview e sia passato prima da qui...
Possiamo comunque accennare altri temi che potrebbero estendere questo set di esercizi: per esempio potremmo chiedere di definire una struttura generica Stack<T> e un paio di metodi della stessa, come pop e push, che permettano l'inserimento e l'estrazione di oggetti generici.
Spostandoci verso il mondo React, un esercizietto carino potrebbe essere la spiegazione della differenza tra useMemo() e useCallback(), o addirittura l'implementazione di una delle due.
Il tempo a disposizione per un colloquio del genere è limitato, ed è possibile che non si riesca a chiedere tutto ciò, molto dipende dal candidato e da quanto velocemente scorrono gli argomenti. Io non so se le domande poste sono troppo facili o troppo difficli, per cui se avete un'opinione al riguardo sarei contentissimo di ricevere qualche feedback, anche con delle idee diverse o dei suggerimenti. Per nostra fortuna, una delle persone intervistate ha risposto brillantemente a quasi tutti i quesiti ed ora è un elemento molto apprezzato da me e dal resto del team!